
Simple big-looped program break down
-
If it's an array of objects, yes, everything is destroyed. If it's an array of pointer, it's your duty to first cleanup.
As for passing stuff around, it will depend on how you pass them around (by value, reference, const reference, pointer).
If passing by value, it's indeed a copy that is done.
@SGaist thank you! I just made some experiments
Step by step I see the things you explain :) -
@SGaist Oh thank you!
one thing I can't find in Internet.
If the variable is local (accessible inside the specific function, let's say the variable int a[3]) does that mean that after the fuction is finished that local variable will be deleted and the memory will be freed?
And also if I transfer the variable (not a pointer but something like int a[3]) from one function to another then the variable is copied and it takes more space in my RAM (about twice more space)?@Please_Help_me_D
For arrays: in the C family of languages, and most "general" programming languages, arrays are passed by reference, not by value.This if you declare a simple
int fredand pass to a functionfunc(int param), the value infredis copied intoparam(and changing it inside the function has no effect on the caller'sfred).OTOH, if you declare an array
int fred[3]and pass to a functionfunc(int *param)the array is passed by reference/pointer, i.e. C passes the address of the start of the array (and changing values at*paramorparam[2]does change what is in thefredarray back in the caller). The obvious reason is that arrays can be large, so you don't want to have to copy them unless you have to.So in your example, when you pass your array (
int[3]) to another function it does not "take twice the space in RAM". The only thing that takes more space is the pointer to the array in the receiving function, which is a fixed 4 or 8 bytes (32-/64-bit) regardless of whether the array itself occupies 400MB of RAM.Meanwhile, going back to your timings. I am surprised if the time to fill your
QVectoris as large as 10 seconds. I don't do C++ so I can't check. I was going to suggest tryinga.resize()ora.reserve()before the loop, but I think the constructor has already done that. One possibility is that (I believe)QVectorwill do bounds checking each time on youra[i], which the pure C++ example above it will not do, and that will cost some. Instead of indexing byi, try using https://doc.qt.io/qt-5/qvector.html#begin etc. to do the fill via iterators and see if that is quicker? The other possibility is thatQVectordata is implicitly shared (https://doc.qt.io/qt-5/implicit-sharing.html). The Qt experts here may be able to indicate whether by changing its content in a loop there is an overhead in dealing with the shared storage area, I don't know. -
@JonB I read about the memory segmentation on heap and stack. I understand the basics I hope.
So I have some doubt about the following: here are three ways to declare an array:int a[3]; int *pa = new int [3]; QVector<int> a(3);Are all of them stored on heap?
I just made an experiment to see which way is the fastest to fill an array:int *pa = new int [100000000]; clock_t start_time = clock(); // start time for (int i = 0; i < 100000000; i++) { pa[i] = i; } clock_t end_time = clock(); // end time clock_t d_time = end_time - start_time; // delta time cout << d_time << endl;Delta time is in range from 0.25 to 1 second (usually less then 1 sec).
QVector<int> a(100000000); clock_t start_time = clock(); // start time for (int i = 0; i < 100000000; i++) { a[i] = i; } clock_t end_time = clock(); // end time clock_t d_time = end_time - start_time; // delta time cout << d_time << endl;Delta time is in range from 8 to 11 second.
I think there should be an explanation to the fact that QVector is so slow compared to pointer-array (standart C++ array).
@SGaist yes)) and that is why I use x64 compilator :)I did some test on my own, because its an interesting topic:
#include <iostream> #include <QVector> #include <vector> #include <numeric> #include <QElapsedTimer> int main(int argc, char *argv[]) { QApplication a(argc, argv); QElapsedTimer et; qint64 t1, t2, t3, t4; int *pa = new int [100000000]; et.start(); for (int i = 0; i < 100000000; i++) { pa[i] = i; } t1 = et.elapsed(); QVector<int> qva(100000000); et.restart(); for (int i = 0; i < 100000000; i++) { qva[i] = i; } t2 = et.restart(); std::iota(qva.begin(), qva.end(), 0); t3 = et.restart(); int j(0); for( int & i : qva){ i = j++; } t4 = et.elapsed(); qDebug() << "Times:"; qDebug() << t1 << t2 << t3 << t4; }The results are:
Debug build: 456 3889 224 214
Release build: 0 86 58 45And that's to be expected- Vector is a complex class and therefore lot of debug information /checks, stuff that will slow it down.
I'm however surprised, that in release the good old C loop is so fast. Maybe the compiler optimizes a lot and the loop is not executed at all 🤔
In release, all methods are pretty close, and the iterator methods , not surprisingly, a good but faster than the access method
Be aware of the Qt Code of Conduct, when posting : https://forum.qt.io/topic/113070/qt-code-of-conduct
Q: What's that?
A: It's blue light.
Q: What does it do?
A: It turns blue. -
I did some test on my own, because its an interesting topic:
#include <iostream> #include <QVector> #include <vector> #include <numeric> #include <QElapsedTimer> int main(int argc, char *argv[]) { QApplication a(argc, argv); QElapsedTimer et; qint64 t1, t2, t3, t4; int *pa = new int [100000000]; et.start(); for (int i = 0; i < 100000000; i++) { pa[i] = i; } t1 = et.elapsed(); QVector<int> qva(100000000); et.restart(); for (int i = 0; i < 100000000; i++) { qva[i] = i; } t2 = et.restart(); std::iota(qva.begin(), qva.end(), 0); t3 = et.restart(); int j(0); for( int & i : qva){ i = j++; } t4 = et.elapsed(); qDebug() << "Times:"; qDebug() << t1 << t2 << t3 << t4; }The results are:
Debug build: 456 3889 224 214
Release build: 0 86 58 45And that's to be expected- Vector is a complex class and therefore lot of debug information /checks, stuff that will slow it down.
I'm however surprised, that in release the good old C loop is so fast. Maybe the compiler optimizes a lot and the loop is not executed at all 🤔
In release, all methods are pretty close, and the iterator methods , not surprisingly, a good but faster than the access method
@J-Hilk said in Simple big-looped program break down:
Maybe the compiler optimizes a lot and the loop is not executed at all 🤔
If he had been filling the elements with a constant value that would have been possible. But because he/you is filling with changing
ieach time, I can't see any optimization of that is possible, it will have to loop! You could look at the disassembly... :) -
@J-Hilk said in Simple big-looped program break down:
Maybe the compiler optimizes a lot and the loop is not executed at all 🤔
If he had been filling the elements with a constant value that would have been possible. But because he/you is filling with changing
ieach time, I can't see any optimization of that is possible, it will have to loop! You could look at the disassembly... :)@JonB I did, even with only level 1 optimization, the loop is removed 🤷♂️
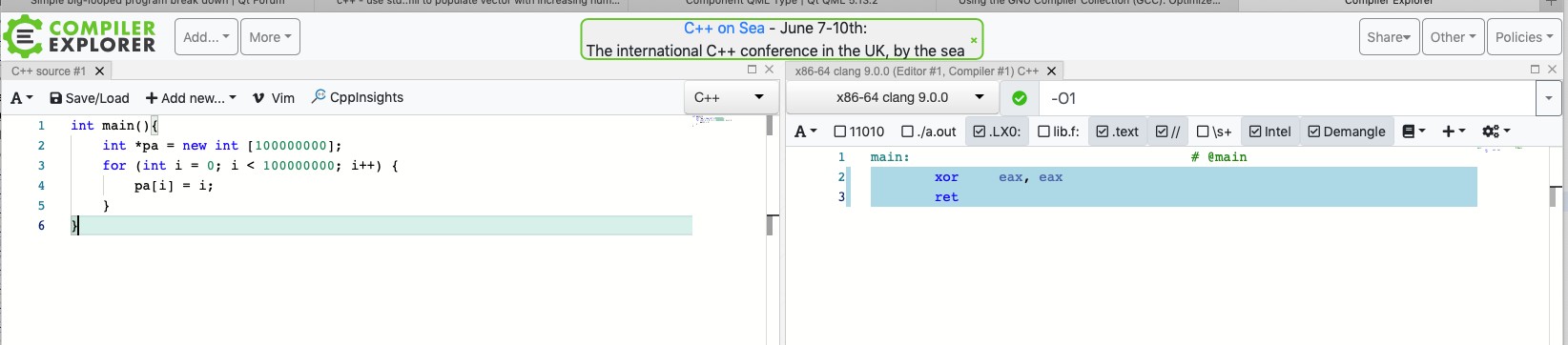
smart things these compilers 😉
Be aware of the Qt Code of Conduct, when posting : https://forum.qt.io/topic/113070/qt-code-of-conduct
Q: What's that?
A: It's blue light.
Q: What does it do?
A: It turns blue. -
@JonB I did, even with only level 1 optimization, the loop is removed 🤷♂️
smart things these compilers 😉
@J-Hilk
Noooooo!!!xor eax, eax retThose two lines just load
eaxwith0(quicker than literal "load with 0") and return it as result --- it's an implicitreturn 0at the end ofmain()!Believe me, somewhere there above it is the code for the loop :) Otherwise, if the compiler has really decided there are no side-effects because
pais never referenced so it will go on strike and do nothing, put areturn pa[10]or something after your loop. -
@J-Hilk
Noooooo!!!xor eax, eax retThose two lines just load
eaxwith0(quicker than literal "load with 0") and return it as result --- it's an implicitreturn 0at the end ofmain()!Believe me, somewhere there above it is the code for the loop :) Otherwise, if the compiler has really decided there are no side-effects because
pais never referenced so it will go on strike and do nothing, put areturn pa[10]or something after your loop.@JonB actually, when I change the compiler to MSVC, the loop will never be removed, even with O3
🤨 Windows, am I right!?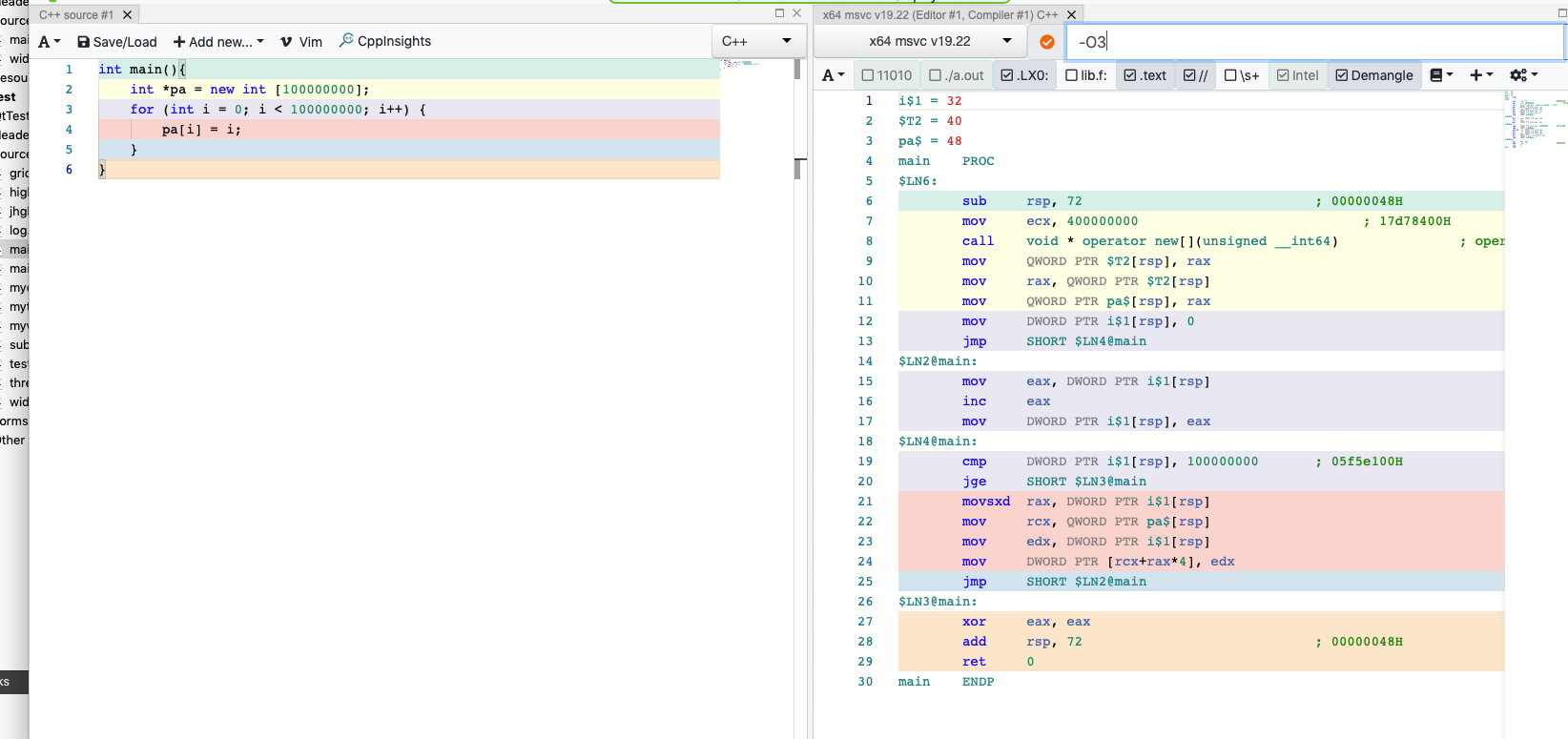
Be aware of the Qt Code of Conduct, when posting : https://forum.qt.io/topic/113070/qt-code-of-conduct
Q: What's that?
A: It's blue light.
Q: What does it do?
A: It turns blue. -
@JonB actually, when I change the compiler to MSVC, the loop will never be removed, even with O3
🤨 Windows, am I right!? -
@J-Hilk
Yep, that's more like it, good old MSVC! As I said, retrygccwithreturn pa[10]after the loop and then see?@JonB said in Simple big-looped program break down:
return pa[10]
you're right by returning pa[10] from main, the release timings look much more like I would have expected:
211 84 52 52
-
@Please_Help_me_D
For arrays: in the C family of languages, and most "general" programming languages, arrays are passed by reference, not by value.This if you declare a simple
int fredand pass to a functionfunc(int param), the value infredis copied intoparam(and changing it inside the function has no effect on the caller'sfred).OTOH, if you declare an array
int fred[3]and pass to a functionfunc(int *param)the array is passed by reference/pointer, i.e. C passes the address of the start of the array (and changing values at*paramorparam[2]does change what is in thefredarray back in the caller). The obvious reason is that arrays can be large, so you don't want to have to copy them unless you have to.So in your example, when you pass your array (
int[3]) to another function it does not "take twice the space in RAM". The only thing that takes more space is the pointer to the array in the receiving function, which is a fixed 4 or 8 bytes (32-/64-bit) regardless of whether the array itself occupies 400MB of RAM.Meanwhile, going back to your timings. I am surprised if the time to fill your
QVectoris as large as 10 seconds. I don't do C++ so I can't check. I was going to suggest tryinga.resize()ora.reserve()before the loop, but I think the constructor has already done that. One possibility is that (I believe)QVectorwill do bounds checking each time on youra[i], which the pure C++ example above it will not do, and that will cost some. Instead of indexing byi, try using https://doc.qt.io/qt-5/qvector.html#begin etc. to do the fill via iterators and see if that is quicker? The other possibility is thatQVectordata is implicitly shared (https://doc.qt.io/qt-5/implicit-sharing.html). The Qt experts here may be able to indicate whether by changing its content in a loop there is an overhead in dealing with the shared storage area, I don't know.@JonB I'm trying to understand how to adjust QVectror::iterator to assign values to an array. I did the following:
QVector<int> a = {10, 20, 30, 40, 50}; QVector<int>::iterator it = a.begin(); clock_t start_time = clock(); while (it != a.end()) { cout << *it << endl; it++; }but that just showed me what is the iterator. How to modify the code to fill an empty QVector with numbers?
-
@JonB I'm trying to understand how to adjust QVectror::iterator to assign values to an array. I did the following:
QVector<int> a = {10, 20, 30, 40, 50}; QVector<int>::iterator it = a.begin(); clock_t start_time = clock(); while (it != a.end()) { cout << *it << endl; it++; }but that just showed me what is the iterator. How to modify the code to fill an empty QVector with numbers?
@Please_Help_me_D said in Simple big-looped program break down:
int i = 0; while (it != a.end()) { *it = i++; it++; } -
@Please_Help_me_D said in Simple big-looped program break down:
int i = 0; while (it != a.end()) { *it = i++; it++; }@JonB So the execution time for the code:
QVector<int> a(100000000); QVector<int>::iterator it = a.begin(); int i = 0; clock_t start_time = clock(); // начальное время while (it != a.end()) { *it = i++; it++; } clock_t end_time = clock(); // конечное время clock_t d_time = end_time - start_time; cout << d_time << endl;is 8-9 seconds
By the way, the same operation in Matlab with single (float) precision accuracy takes 0.3 seconds. That means that Matlab loops not so slow as I thought:// Matlab code a = single(zeros(100000000,1)); // preallocate the memory tic // start time for n = 1:100000000 a(n) = single(n); // assign avlue to each position end toc // end time -
@JonB So the execution time for the code:
QVector<int> a(100000000); QVector<int>::iterator it = a.begin(); int i = 0; clock_t start_time = clock(); // начальное время while (it != a.end()) { *it = i++; it++; } clock_t end_time = clock(); // конечное время clock_t d_time = end_time - start_time; cout << d_time << endl;is 8-9 seconds
By the way, the same operation in Matlab with single (float) precision accuracy takes 0.3 seconds. That means that Matlab loops not so slow as I thought:// Matlab code a = single(zeros(100000000,1)); // preallocate the memory tic // start time for n = 1:100000000 a(n) = single(n); // assign avlue to each position end toc // end time@Please_Help_me_D
If anything, than you should take away from my test, that there's a difference between release and debug builds in c++build and run your test in release, it will drop way below 1 sec
Be aware of the Qt Code of Conduct, when posting : https://forum.qt.io/topic/113070/qt-code-of-conduct
Q: What's that?
A: It's blue light.
Q: What does it do?
A: It turns blue. -
@JonB So the execution time for the code:
QVector<int> a(100000000); QVector<int>::iterator it = a.begin(); int i = 0; clock_t start_time = clock(); // начальное время while (it != a.end()) { *it = i++; it++; } clock_t end_time = clock(); // конечное время clock_t d_time = end_time - start_time; cout << d_time << endl;is 8-9 seconds
By the way, the same operation in Matlab with single (float) precision accuracy takes 0.3 seconds. That means that Matlab loops not so slow as I thought:// Matlab code a = single(zeros(100000000,1)); // preallocate the memory tic // start time for n = 1:100000000 a(n) = single(n); // assign avlue to each position end toc // end time -
@Please_Help_me_D
If anything, than you should take away from my test, that there's a difference between release and debug builds in c++build and run your test in release, it will drop way below 1 sec
@J-Hilk sorry I forgot that!
int *pa = new int [100000000]; clock_t start_time = clock(); for (int i = 0; i < 100000000; i++) { pa[i] = i; } clock_t end_time = clock(); clock_t d_time = end_time - start_time; cout << d_time << endl;is 0.14 second
QVector<int> a(100000000); clock_t start_time = clock(); for (int i = 0; i < 100000000; i++) { a[i] = i; } clock_t end_time = clock(); clock_t d_time = end_time - start_time; cout << d_time << endl;is also about 0.14 second
QVector<int> a(100000000); QVector<int>::iterator it = a.begin(); / int i = 0; clock_t start_time = clock(); while (it != a.end()) { *it = i++; it++; } clock_t end_time = clock(); clock_t d_time = end_time - start_time; cout << d_time << endl;is also about 0.14 second
So Matlab loops is about twice slower :)
Thank you very much! It's good to know such difference in perfomance in Debug and Release mode -
@Please_Help_me_D
Please do as @J-Hilk has said before, if you're compiling or running for debug there will be a vast difference from release/optimizedAlso separately, verify what the MATLAB does in your code with
for n = 1:100000001@JonB Matlab automatically increases the vector size by 1. But if I dont preallocate the size of the vector and with each iteration the vector size increases then it takes way much time. Here I do the iteration without preallocation and variable "a" is created when first iteration is performed:
// Matlab code tic for n = 1:100000000 a(n) = single(n); end toc35 seconds to preform
-
@JonB Matlab automatically increases the vector size by 1. But if I dont preallocate the size of the vector and with each iteration the vector size increases then it takes way much time. Here I do the iteration without preallocation and variable "a" is created when first iteration is performed:
// Matlab code tic for n = 1:100000000 a(n) = single(n); end toc35 seconds to preform
@Please_Help_me_D
For presumably similar slowness withQVector, try creating it empty with justQVector<int> aand usea.append(i)in the loop. I anticipate some slowness compared to pre-sizing, but (hopefully) not as bad as it could be:This operation is relatively fast, because
QVectortypically allocates more memory than necessary, so it can grow without reallocating the entire vector each time. -
@Please_Help_me_D
For presumably similar slowness withQVector, try creating it empty with justQVector<int> aand usea.append(i)in the loop. I anticipate some slowness compared to pre-sizing, but (hopefully) not as bad as it could be:This operation is relatively fast, because
QVectortypically allocates more memory than necessary, so it can grow without reallocating the entire vector each time.@JonB very interesting result as for me:
QVector<int> a; clock_t start_time = clock(); for (int i = 0; i < 100000000; i++) { a.append(i); } clock_t end_time = clock(); clock_t d_time = end_time - start_time; cout << d_time << endl;in Debug mode it takes 5.5-6 seconds
in Release mode it takes 0.7 second (while in Matlab as I previously said it takes 35 seconds)
So QVectror is really fast even if it works with <appending mode>
Thank you for this example! -
@JonB very interesting result as for me:
QVector<int> a; clock_t start_time = clock(); for (int i = 0; i < 100000000; i++) { a.append(i); } clock_t end_time = clock(); clock_t d_time = end_time - start_time; cout << d_time << endl;in Debug mode it takes 5.5-6 seconds
in Release mode it takes 0.7 second (while in Matlab as I previously said it takes 35 seconds)
So QVectror is really fast even if it works with <appending mode>
Thank you for this example!@Please_Help_me_D said in Simple big-looped program break down:
So QVectror is really fast even if it works with <appending mode>
As far as I know QVector allocates more memory as currently is need and on resizing it allocates again more than "current_size + 1".
-
@Please_Help_me_D said in Simple big-looped program break down:
So QVectror is really fast even if it works with <appending mode>
As far as I know QVector allocates more memory as currently is need and on resizing it allocates again more than "current_size + 1".
@jsulm yes it does.
I tested how much my program weigh with Windows Task Manager for different number of loops (say n) and two mode of QVector (normal and <append>). Here is the result (Debug mode):QVector<int> a(100000000); clock_t start_time = clock(); for (int i = 0; i < 100000000; i++) { a[i] = i; } clock_t end_time = clock(); clock_t d_time = end_time - start_time; cout << d_time << endl;n = 100000000 -> 392464 kilobytes
n = 100000000/2 -> 196780 kilobytes
n = 100000000/4 -> 98936 kilobytes
n = 100000000/8 -> 50008 kilobytes
!_____________________________!QVector<int> a; clock_t start_time = clock(); for (int i = 0; i < 100000000; i++) { a.append(i); } clock_t end_time = clock(); clock_t d_time = end_time - start_time; cout << d_time << endl;n = 100000000 -> 527456 kilobytes
n = 100000000/2 -> 264804 kilobytes
n = 100000000/4 -> 133468 kilobytes
n = 100000000/8 -> 67804 kilobytesIf I use simple C++ array insead of QVector then for n = 100000000 -> 391780 kilobytes (almost the same as simple QVector).
So the conclusion I see is that QVector in <append> mode weighs 1.35 times simple QVector or C++ array