
Reordering rows of QTableView with drag and drop
-
I'm sorry! I completely forgot.
I just downloaded it. Thestd::bindversion works out of the box when you fix the inheritance error (look down for details).Otherwise there's an argument order error for the runtime resolution method:
QMetaObject::invokeMethod(this, "selectRow", Qt::QueuedConnection, Q_ARG(int, m_dropRow));The inheritance error, though, affects both invocations:
class MyTableView: QTableViewinherits privately, it should be:
class MyTableView: public QTableViewHi @kshegunov ,
Now I had time to experiment with your suggestion but I am not seeing how it may solve the problem.
I've updated with GitHub repository with it if anyone wishes to run it.
There are several things I do not understand:
- The main one is that I don't see the stated desired effect: I wanted the dropping a row into another to insert itself rather than overwrite, but it still overwrites.
- Another thing that puzzles me is that, when I drag a row in between two rows, it used to insert itself there (as is the standard behavior), but now it also overwrites. That is to say, it seems to have gone in the opposite direction of what was desired.
- It seems to me your code has the purpose of selecting the row after drag and drop, but I don't see that behavior. There is no selection after the operation.
Would you please shed some light on these questions? Thanks again.
-
Hi @kshegunov ,
Now I had time to experiment with your suggestion but I am not seeing how it may solve the problem.
I've updated with GitHub repository with it if anyone wishes to run it.
There are several things I do not understand:
- The main one is that I don't see the stated desired effect: I wanted the dropping a row into another to insert itself rather than overwrite, but it still overwrites.
- Another thing that puzzles me is that, when I drag a row in between two rows, it used to insert itself there (as is the standard behavior), but now it also overwrites. That is to say, it seems to have gone in the opposite direction of what was desired.
- It seems to me your code has the purpose of selecting the row after drag and drop, but I don't see that behavior. There is no selection after the operation.
Would you please shed some light on these questions? Thanks again.
@Rodrigo-B said in Reordering rows of QTableView with drag and drop:
Now I had time to experiment with your suggestion but I am not seeing how it may solve the problem.
That's because I'd forgotten a method. I'm sorry, it happens sometimes when you snip pieces from existing code without thinking too much. I've created a pull request for you, so you could check it out.
-
@Rodrigo-B said in Reordering rows of QTableView with drag and drop:
Now I had time to experiment with your suggestion but I am not seeing how it may solve the problem.
That's because I'd forgotten a method. I'm sorry, it happens sometimes when you snip pieces from existing code without thinking too much. I've created a pull request for you, so you could check it out.
@kshegunov Thank you, I really appreciate that you went over the code and provided a pull request! However, it still doesn't seem to work. When I drop the first row (Lion) on third row (Mouse), I would expect the Lion row to be inserted right below Mouse, and Gazelle to move up and be the first row. Instead, Lion overwrites Gazelle in the second row and remains in the first row. As far as I can tell, everything is being overwritten rather than moved.
In any case, I am starting to see the idea here... modifying variables in dropMimeData so data goes where we want. So if you don't have the time to look into this I will probably be able to mess around and find a solution. Thanks!
-
@kshegunov Thank you, I really appreciate that you went over the code and provided a pull request! However, it still doesn't seem to work. When I drop the first row (Lion) on third row (Mouse), I would expect the Lion row to be inserted right below Mouse, and Gazelle to move up and be the first row. Instead, Lion overwrites Gazelle in the second row and remains in the first row. As far as I can tell, everything is being overwritten rather than moved.
In any case, I am starting to see the idea here... modifying variables in dropMimeData so data goes where we want. So if you don't have the time to look into this I will probably be able to mess around and find a solution. Thanks!
@Rodrigo-B said in Reordering rows of QTableView with drag and drop:
Instead, Lion overwrites Gazelle in the second row and remains in the first row. As far as I can tell, everything is being overwritten rather than moved.
That's odd, because it works on linux as described.
Video: https://drive.google.com/file/d/14vvAHgGdyRoJkKqgm_tbT8uRwKt_3JhL/view?usp=sharing -
@Rodrigo-B said in Reordering rows of QTableView with drag and drop:
Instead, Lion overwrites Gazelle in the second row and remains in the first row. As far as I can tell, everything is being overwritten rather than moved.
That's odd, because it works on linux as described.
Video: https://drive.google.com/file/d/14vvAHgGdyRoJkKqgm_tbT8uRwKt_3JhL/view?usp=sharing@kshegunov Wow, that's mindblogging! Here's my video showing that my local code is sync'ed with the repository containing your change, and behaving completely differently:
https://drive.google.com/file/d/11m9d5xOGGhJN-WM-OhRjHAhGK1_t7vMR/view?usp=sharing
Not quite sure how to proceed now other than submitting as a bug...
-
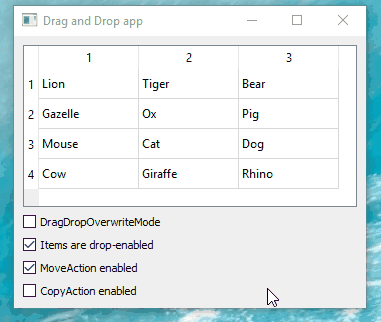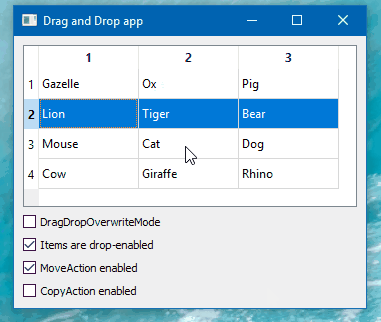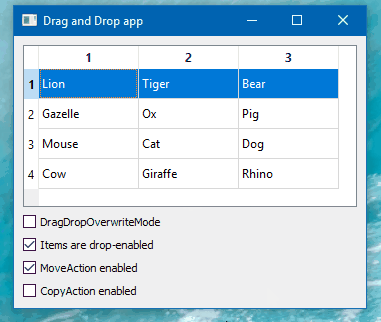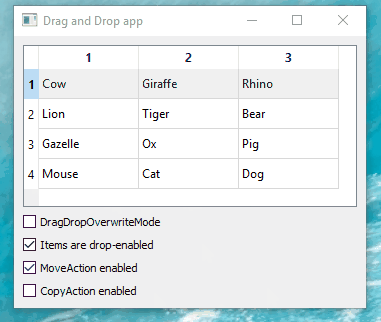
Hi
Just as a note. Win 10. Qt5.15.2
seems to work as expected:
-
@kshegunov Wow, that's mindblogging! Here's my video showing that my local code is sync'ed with the repository containing your change, and behaving completely differently:
https://drive.google.com/file/d/11m9d5xOGGhJN-WM-OhRjHAhGK1_t7vMR/view?usp=sharing
Not quite sure how to proceed now other than submitting as a bug...
@Rodrigo-B said in Reordering rows of QTableView with drag and drop:
Wow, that's mindblogging!
I imagine there's something different on MacOS in the way the drag&drop is handled. But as I said I haven't and I don't own a mac and I've never tested that code on it, so I truly have no idea what it may be, sorry.
Not quite sure how to proceed now other than submitting as a bug...
Yes, you're welcome to do that, although if I were you I wouldn't hold my breath.
Note:
Not sure if it's relevant, but I noticed how you start the application (from the run button). Make sure you've made a full rebuild before testing, you may have stale code. -
@Rodrigo-B said in Reordering rows of QTableView with drag and drop:
Wow, that's mindblogging!
I imagine there's something different on MacOS in the way the drag&drop is handled. But as I said I haven't and I don't own a mac and I've never tested that code on it, so I truly have no idea what it may be, sorry.
Not quite sure how to proceed now other than submitting as a bug...
Yes, you're welcome to do that, although if I were you I wouldn't hold my breath.
Note:
Not sure if it's relevant, but I noticed how you start the application (from the run button). Make sure you've made a full rebuild before testing, you may have stale code.@kshegunov said in Reordering rows of QTableView with drag and drop:
Note:
Not sure if it's relevant, but I noticed how you start the application (from the run button). Make sure you've made a full rebuild before testing, you may have stale code.Unfortunately things don't change after a Clean and Rebuild (nice observation though).
Alright, I will keep messing with it to see if I find out more.
Thanks @mrjj for running it on Windows, and thanks @kshegunov very much for your help!
-
@Rodrigo-B said in Reordering rows of QTableView with drag and drop:
Wow, that's mindblogging!
I imagine there's something different on MacOS in the way the drag&drop is handled. But as I said I haven't and I don't own a mac and I've never tested that code on it, so I truly have no idea what it may be, sorry.
Not quite sure how to proceed now other than submitting as a bug...
Yes, you're welcome to do that, although if I were you I wouldn't hold my breath.
Note:
Not sure if it's relevant, but I noticed how you start the application (from the run button). Make sure you've made a full rebuild before testing, you may have stale code.Update/good news: when I remove your overriding implementation of
MyTableView::dropEvent, things work fine (although we lose the selection persistence after the drop, as was the goal of that piece of code).Actually, if I keep the method but replace the delayed row selection by
selectRow(m_dropRow)(as shown below), I get the anomalous behavior. If I remove this line, things work properly but without selecting the moved row afterwards.It seems the delayed row selection does not work in the Mac (makes sense since probably different OSs deal with events differently). Then the row selection happens before the dropMimeData and changes the targeted row, causing the bizarre behavior we observed.
void dropEvent(QDropEvent *e) { if (e->source() != this || e->dropAction() != Qt::MoveAction) return; int dragRow = selectedRow(); QTableView::dropEvent(e); // m_dropRow is set by inserted row if (m_dropRow > dragRow) --m_dropRow; selectRow(m_dropRow); // non-delayed selection has the same effect, so QueuedConnection seems not to work on the Mac. // QMetaObject::invokeMethod(this, // std::bind(&MyTableView::selectRow, this, m_dropRow), // Qt::QueuedConnection); // Postpones selection } -
Update/good news: when I remove your overriding implementation of
MyTableView::dropEvent, things work fine (although we lose the selection persistence after the drop, as was the goal of that piece of code).Actually, if I keep the method but replace the delayed row selection by
selectRow(m_dropRow)(as shown below), I get the anomalous behavior. If I remove this line, things work properly but without selecting the moved row afterwards.It seems the delayed row selection does not work in the Mac (makes sense since probably different OSs deal with events differently). Then the row selection happens before the dropMimeData and changes the targeted row, causing the bizarre behavior we observed.
void dropEvent(QDropEvent *e) { if (e->source() != this || e->dropAction() != Qt::MoveAction) return; int dragRow = selectedRow(); QTableView::dropEvent(e); // m_dropRow is set by inserted row if (m_dropRow > dragRow) --m_dropRow; selectRow(m_dropRow); // non-delayed selection has the same effect, so QueuedConnection seems not to work on the Mac. // QMetaObject::invokeMethod(this, // std::bind(&MyTableView::selectRow, this, m_dropRow), // Qt::QueuedConnection); // Postpones selection }Followup question for the community: it seems changes to drag and drop often happen in dropMimeData, as @kshegunov suggested above.
However, that seems like a less than ideal solution because if violates the Model-View paradigm. The behavior of drag and drop seems to be more related to the view than to the model. For example, I might want to use the same model in two different views but wish to see the behavior described in only one of those views.
Would it be possible to obtain the same behavior but overriding view methods only?
-
Apologies if this is a repeat of known info... the thread seemed to have delved off topic for a bit so maybe I missed it.
@Rodrigo-B said in Reordering rows of QTableView with drag and drop:
However, dropping D on R overwrites R, even if the QTableView's property dragDropOverwriteMode is false.
I always thought this behavior was strange as well.
I work around the issue by returning
falsefrom my model'sdropMimeData()method in response toQt::MoveActionfrom any of the built-in "QItemView" classes. Even if the move succeeded. I've already done the moving insidedropMimeData()and the model has already updated, so the View will reflect it regardless of what we return there. Returningfalsemakes the item views cancel any further action, like removing any rows(*). It's not ideal since the actualQDragnever gets properlyaccepted, but I also haven't seen that it matters.If I want to DnD from my own custom views (or I've re-implemented
QAbstractItemView::startDrag()) then I can pass some meta data to my model'sdropMimeData()which will trigger the correcttrue/falseresult of the drop (eg. if I'm only drag/dropping rows, I can passcolumn = -2and the model knows to return the actual result instead of alwaysfalse).*More specifically, inQAbstractItemView::startDrag()[1] where it waits for thedrag.exec() == Qt::MoveAction, it will then not run the internald->clearOrRemove()method, which is what does the actual removals. Another way to hack it may be to change the accepted drop method by re-implementing the (simpler)QAbstractItemView::dropEvent[2].HTH,
-Max[1] https://code.woboq.org/qt5/qtbase/src/widgets/itemviews/qabstractitemview.cpp.html#_ZN17QAbstractItemView9startDragE6QFlagsIN2Qt10DropActionEE
[2] https://code.woboq.org/qt5/qtbase/src/widgets/itemviews/qabstractitemview.cpp.html#_ZN17QAbstractItemView9dropEventEP10QDropEvent -
Followup question for the community: it seems changes to drag and drop often happen in dropMimeData, as @kshegunov suggested above.
However, that seems like a less than ideal solution because if violates the Model-View paradigm. The behavior of drag and drop seems to be more related to the view than to the model. For example, I might want to use the same model in two different views but wish to see the behavior described in only one of those views.
Would it be possible to obtain the same behavior but overriding view methods only?
@Rodrigo-B said in Reordering rows of QTableView with drag and drop:
Followup question for the community: it seems changes to drag and drop often happen in dropMimeData, as @kshegunov suggested above.
However, that seems like a less than ideal solution because if violates the Model-View paradigm. The behavior of drag and drop seems to be more related to the view than to the model. For example, I might want to use the same model in two different views but wish to see the behavior described in only one of those views.
Can you post a more concrete example? I think everything your model needs to know to perform the appropriate drop action is passed to
dropMimeData(). I'm having trouble thinking of a situation where the "view" would know better what to do with the data than the model would. One could dis/allow certain moves in the view, but there's no way the view can do a move/update if the underlying model can't handle it.The default
QAbstract*Model::dropMimeData()methods are convenient, but relatively simplistic. Re-implementing provides a lot more control.Cheers,
-Max -
@Rodrigo-B said in Reordering rows of QTableView with drag and drop:
Followup question for the community: it seems changes to drag and drop often happen in dropMimeData, as @kshegunov suggested above.
However, that seems like a less than ideal solution because if violates the Model-View paradigm. The behavior of drag and drop seems to be more related to the view than to the model. For example, I might want to use the same model in two different views but wish to see the behavior described in only one of those views.
Can you post a more concrete example? I think everything your model needs to know to perform the appropriate drop action is passed to
dropMimeData(). I'm having trouble thinking of a situation where the "view" would know better what to do with the data than the model would. One could dis/allow certain moves in the view, but there's no way the view can do a move/update if the underlying model can't handle it.The default
QAbstract*Model::dropMimeData()methods are convenient, but relatively simplistic. Re-implementing provides a lot more control.Cheers,
-Max@Max-Paperno said in Reordering rows of QTableView with drag and drop:
Can you post a more concrete example? I think everything your model needs to know to perform the appropriate drop action is passed to dropMimeData().
I believe @Rodrigo-B's point is that the model is not supposed to perform any appropriate drop actions at all.
I'm having trouble thinking of a situation where the "view" would know better what to do with the data than the model would.
Why? Say you have an object of type
Xand a widget representing that object for the user to edit. Would you implement the drag-drop handling in the classXor in the widget class? I'd rather do it in the UI, at least to me it looks more in line with what d&d does. If myXclass is also possible to be used without UI, then I'd have no drag-drop at all, so it does seem "wrong" to force it to deal with it ... -
@Max-Paperno said in Reordering rows of QTableView with drag and drop:
Can you post a more concrete example? I think everything your model needs to know to perform the appropriate drop action is passed to dropMimeData().
I believe @Rodrigo-B's point is that the model is not supposed to perform any appropriate drop actions at all.
I'm having trouble thinking of a situation where the "view" would know better what to do with the data than the model would.
Why? Say you have an object of type
Xand a widget representing that object for the user to edit. Would you implement the drag-drop handling in the classXor in the widget class? I'd rather do it in the UI, at least to me it looks more in line with what d&d does. If myXclass is also possible to be used without UI, then I'd have no drag-drop at all, so it does seem "wrong" to force it to deal with it ...Right, certainly the UI is the "first stop" with DnD, and it can and does control, to a large extent, how the user can "physically" interact with the data. But ultimately it's up to the model how to react to those results (move, copy, overwrite, edit, etc). If, for example, you don't want the UI to allow the user to replace (move-overwrite) an item by dropping another onto it, then that move can be prohibited in the UI (or like in the OP, replaced with a move-only action). But the model has to do the actual data manipulation, otherwise that breaks the model/view separation. If the model "can't" do what the UI is telling it (for whatever reason, including data integrity), then it shouldn't be forced to. Especially considering that the model should be the one to encode and decode the MIME data since it would be a) most "familiar" with it and b) is a convenient central place to keep that functionality (and not just for views).
Also just to point out that the "drop" part in
dropMimeData()(et. al.) makes it sound limited to DnD. Actually the same method can be used to paste clipboard data, for example, or any other kind of import/export action where MIME-encapsulated data makes sense.Of course one is also free to re-implement the respective DnD methods in the views (or write custom views) and do all the data manipulation of the model from there (using the respective insert/remove/move methods). Including en/decoding the data. But the default behavior is to let the model handle that part.
I might even go out on a limb and say that the main reason for this topic is that the UI is doing something unexpected by trying to be "smart" about what to do with the data after it has been dropped. From my POV it should not try to manipulate the data after the model has done its thing... ever (keep selection maybe, but that has nothing to do with the model). The UI should be telling the model exactly what to do... eg. if dropping a row onto another row is meant to re-arrange the items (not overwrite the recipient), then the view needs to send the appropriate combination of action, row number, and parent. Then the model knows, oh, this row should be moved before this other one, not replaced. The view really does have ultimate control over what to tell the model it wants to do.
Cheers,
-Max -
Right, certainly the UI is the "first stop" with DnD, and it can and does control, to a large extent, how the user can "physically" interact with the data. But ultimately it's up to the model how to react to those results (move, copy, overwrite, edit, etc). If, for example, you don't want the UI to allow the user to replace (move-overwrite) an item by dropping another onto it, then that move can be prohibited in the UI (or like in the OP, replaced with a move-only action). But the model has to do the actual data manipulation, otherwise that breaks the model/view separation. If the model "can't" do what the UI is telling it (for whatever reason, including data integrity), then it shouldn't be forced to. Especially considering that the model should be the one to encode and decode the MIME data since it would be a) most "familiar" with it and b) is a convenient central place to keep that functionality (and not just for views).
Also just to point out that the "drop" part in
dropMimeData()(et. al.) makes it sound limited to DnD. Actually the same method can be used to paste clipboard data, for example, or any other kind of import/export action where MIME-encapsulated data makes sense.Of course one is also free to re-implement the respective DnD methods in the views (or write custom views) and do all the data manipulation of the model from there (using the respective insert/remove/move methods). Including en/decoding the data. But the default behavior is to let the model handle that part.
I might even go out on a limb and say that the main reason for this topic is that the UI is doing something unexpected by trying to be "smart" about what to do with the data after it has been dropped. From my POV it should not try to manipulate the data after the model has done its thing... ever (keep selection maybe, but that has nothing to do with the model). The UI should be telling the model exactly what to do... eg. if dropping a row onto another row is meant to re-arrange the items (not overwrite the recipient), then the view needs to send the appropriate combination of action, row number, and parent. Then the model knows, oh, this row should be moved before this other one, not replaced. The view really does have ultimate control over what to tell the model it wants to do.
Cheers,
-Max@Max-Paperno said in Reordering rows of QTableView with drag and drop:
Right, certainly the UI is the "first stop" with DnD, and it can and does control, to a large extent, how the user can "physically" interact with the data. But ultimately it's up to the model how to react to those results (move, copy, overwrite, edit, etc).
Yet it doesn't. It reacts directly to the raw representation, not to the
move, not to thecopy. The model is the one unpacking and interpreting the mime-data. Which is the gist of my whole argument.If, for example, you don't want the UI to allow the user to replace (move-overwrite) an item by dropping another onto it, then that move can be prohibited in the UI (or like in the OP, replaced with a move-only action). But the model has to do the actual data manipulation, otherwise that breaks the model/view separation.
The model should expose an API to all clients to that API to manipulate the data, which it does. However, it also does interprets what's in the mime-encapsulated data. To bring the argument to an absurdity, why not force the model to interpret a TCP protocol? This simply violates the separation of concerns, and I consider it an API bug. Not a significant one, mind you, but still ...
If the model "can't" do what the UI is telling it (for whatever reason, including data integrity), then it shouldn't be forced to.
Yes, but the UI doesn't tell the model "move this row", it tells it, "hey I have this thing, please do what it says inside".
Especially considering that the model should be the one to encode and decode the MIME data since it would be a) most "familiar" with it and b) is a convenient central place to keep that functionality (and not just for views).
Also just to point out that the "drop" part in
dropMimeData()(et. al.) makes it sound limited to DnD. Actually the same method can be used to paste clipboard data, for example, or any other kind of import/export action where MIME-encapsulated data makes sense.Not in my opinion. The moment you start pushing unsanitized user-supplied data over opaque datatypes to a model, that's the moment you break any three-tier validation you may've hoped to achieve. If the data comes through a network channel, you'd not push it directly to the model, be it mime-compatible or not, would you? Neither should you do it with an UI.
Of course one is also free to re-implement the respective DnD methods in the views (or write custom views) and do all the data manipulation of the model from there (using the respective insert/remove/move methods). Including en/decoding the data. But the default behavior is to let the model handle that part.
Which is what it shouldn't, is the point. It's not its place to interpret what comes from whatever place it happens to come.
I might even go out on a limb and say that the main reason for this topic is that the UI is doing something unexpected by trying to be "smart" about what to do with the data after it has been dropped. From my POV it should not try to manipulate the data after the model has done its thing... ever (keep selection maybe, but that has nothing to do with the model).
And it doesn't. In the proposed fix it's actually necessary to override the model's function to prevent it from overwriting the row. The only thing the view tries to achieve here is to keep the selection, it doesn't modify the drop event at all.
The UI should be telling the model exactly what to do... eg. if dropping a row onto another row is meant to re-arrange the items (not overwrite the recipient), then the view needs to send the appropriate combination of action, row number, and parent. Then the model knows, oh, this row should be moved before this other one, not replaced. The view really does have ultimate control over what to tell the model it wants to do.
Heh, isn't that my argument? The default implementation instead of that passes on the mime-data, instead of saying, "hey, I want you to put me a new row there".
-
@Max-Paperno said in Reordering rows of QTableView with drag and drop:
Right, certainly the UI is the "first stop" with DnD, and it can and does control, to a large extent, how the user can "physically" interact with the data. But ultimately it's up to the model how to react to those results (move, copy, overwrite, edit, etc).
Yet it doesn't. It reacts directly to the raw representation, not to the
move, not to thecopy. The model is the one unpacking and interpreting the mime-data. Which is the gist of my whole argument.If, for example, you don't want the UI to allow the user to replace (move-overwrite) an item by dropping another onto it, then that move can be prohibited in the UI (or like in the OP, replaced with a move-only action). But the model has to do the actual data manipulation, otherwise that breaks the model/view separation.
The model should expose an API to all clients to that API to manipulate the data, which it does. However, it also does interprets what's in the mime-encapsulated data. To bring the argument to an absurdity, why not force the model to interpret a TCP protocol? This simply violates the separation of concerns, and I consider it an API bug. Not a significant one, mind you, but still ...
If the model "can't" do what the UI is telling it (for whatever reason, including data integrity), then it shouldn't be forced to.
Yes, but the UI doesn't tell the model "move this row", it tells it, "hey I have this thing, please do what it says inside".
Especially considering that the model should be the one to encode and decode the MIME data since it would be a) most "familiar" with it and b) is a convenient central place to keep that functionality (and not just for views).
Also just to point out that the "drop" part in
dropMimeData()(et. al.) makes it sound limited to DnD. Actually the same method can be used to paste clipboard data, for example, or any other kind of import/export action where MIME-encapsulated data makes sense.Not in my opinion. The moment you start pushing unsanitized user-supplied data over opaque datatypes to a model, that's the moment you break any three-tier validation you may've hoped to achieve. If the data comes through a network channel, you'd not push it directly to the model, be it mime-compatible or not, would you? Neither should you do it with an UI.
Of course one is also free to re-implement the respective DnD methods in the views (or write custom views) and do all the data manipulation of the model from there (using the respective insert/remove/move methods). Including en/decoding the data. But the default behavior is to let the model handle that part.
Which is what it shouldn't, is the point. It's not its place to interpret what comes from whatever place it happens to come.
I might even go out on a limb and say that the main reason for this topic is that the UI is doing something unexpected by trying to be "smart" about what to do with the data after it has been dropped. From my POV it should not try to manipulate the data after the model has done its thing... ever (keep selection maybe, but that has nothing to do with the model).
And it doesn't. In the proposed fix it's actually necessary to override the model's function to prevent it from overwriting the row. The only thing the view tries to achieve here is to keep the selection, it doesn't modify the drop event at all.
The UI should be telling the model exactly what to do... eg. if dropping a row onto another row is meant to re-arrange the items (not overwrite the recipient), then the view needs to send the appropriate combination of action, row number, and parent. Then the model knows, oh, this row should be moved before this other one, not replaced. The view really does have ultimate control over what to tell the model it wants to do.
Heh, isn't that my argument? The default implementation instead of that passes on the mime-data, instead of saying, "hey, I want you to put me a new row there".
@kshegunov said in Reordering rows of QTableView with drag and drop:
Yes, but the UI doesn't tell the model "move this row", it tells it, "hey I have this thing, please do what it says inside".
Ah yes, you're right. And maybe where the API is lacking. For example, what is the significance of of a
MoveActionif one doesn't know where the data is being moved from? In fact the default ItemModels implementations pretty much ignore theactionattribute indropMimeData()except to validate that's it's not a Link or no-op. And then the UI Views try to compensate for that. I haven't used the default behaviors in so long, I forget how limited they are.Instead I like to encode meta data about the source data (which is being dragged/copied) in
mimeData(), typically as a "header" of another MIME type, or sometimes the data itself has enough details. Then the "canDrop" and "drop" methods know exactly "move this row," like you said. Not some ambiguous "here's some data, plop it in." In fact if data is only going to be moved/copied within the same model (no external destinations), one doesn't even need to encode the data itself, just where it currently lives in the model (itsQ[Persistent]ModelIndex, essentially, or some other unique record ID which is already common in structured data, like a database), which is also much more efficient and easier compared to the default routines. OTOH if the data may move between model instances, then again the destination model can know that the source is external, in which case a "move" operation becomes an insert/replace operation.Personally I think none of this should be handled by the UI at all. Whether the model itself should handle it, or some other helper/proxy class is an implementation detail (personal taste, needs, etc). That's really the main point I was questioning in my original reply to Rodrigo. I don't want to have to create a custom UI for each data model's preferred behavior, after all, I'd rather centralize that functionality, just like the data model is centralized.
The one place this breaks down somewhat is when moving data out of one model and into another. The source model needs to be notified that the data can be safely removed. So the UI, or some other mechanism, does need to do that. But this is pretty basic, eg. if the remote drop (not onto itself) event was accepted as a move, then tell the local model it's OK to delete that data. What is harder is to coordinate cut/paste operations, since there's nothing like a
QDragto monitor.To clarify, I'm talking about manipulating well-structured data sets. If one wants to, say, drop some selected text onto a field and have that text become the new value, that's really a whole different thing (and simpler, I think). Or arbitrarily copy data between models, including adding columns if necessary, which is what using all the built-in defaults basically allows.
The moment you start pushing unsanitized user-supplied data over opaque datatypes to a model, that's the moment you break any three-tier validation you may've hoped to achieve. If the data comes through a network channel, you'd not push it directly to the model, be it mime-compatible or not, would you?
I think this is veering even further off into OT territory... :-) From a data manipulation perspective, cut/copy/paste is just like DnD but with a clipboard object. If one is concerned about validating the MIME data, then that is a factor regardless of how the data is originally obtained (to varying degrees, perhaps, eg. local clipboard vs. Internet stream :-). I certainly don't want any UI component to do that, but again where/how/if this happens is an implementation detail up to the author(s). The validation needs of any particular data/project may vary from just checking the MIME type to running it through a virus checker... who knows.
Best,
-Max -
@kshegunov said in Reordering rows of QTableView with drag and drop:
Yes, but the UI doesn't tell the model "move this row", it tells it, "hey I have this thing, please do what it says inside".
Ah yes, you're right. And maybe where the API is lacking. For example, what is the significance of of a
MoveActionif one doesn't know where the data is being moved from? In fact the default ItemModels implementations pretty much ignore theactionattribute indropMimeData()except to validate that's it's not a Link or no-op. And then the UI Views try to compensate for that. I haven't used the default behaviors in so long, I forget how limited they are.Instead I like to encode meta data about the source data (which is being dragged/copied) in
mimeData(), typically as a "header" of another MIME type, or sometimes the data itself has enough details. Then the "canDrop" and "drop" methods know exactly "move this row," like you said. Not some ambiguous "here's some data, plop it in." In fact if data is only going to be moved/copied within the same model (no external destinations), one doesn't even need to encode the data itself, just where it currently lives in the model (itsQ[Persistent]ModelIndex, essentially, or some other unique record ID which is already common in structured data, like a database), which is also much more efficient and easier compared to the default routines. OTOH if the data may move between model instances, then again the destination model can know that the source is external, in which case a "move" operation becomes an insert/replace operation.Personally I think none of this should be handled by the UI at all. Whether the model itself should handle it, or some other helper/proxy class is an implementation detail (personal taste, needs, etc). That's really the main point I was questioning in my original reply to Rodrigo. I don't want to have to create a custom UI for each data model's preferred behavior, after all, I'd rather centralize that functionality, just like the data model is centralized.
The one place this breaks down somewhat is when moving data out of one model and into another. The source model needs to be notified that the data can be safely removed. So the UI, or some other mechanism, does need to do that. But this is pretty basic, eg. if the remote drop (not onto itself) event was accepted as a move, then tell the local model it's OK to delete that data. What is harder is to coordinate cut/paste operations, since there's nothing like a
QDragto monitor.To clarify, I'm talking about manipulating well-structured data sets. If one wants to, say, drop some selected text onto a field and have that text become the new value, that's really a whole different thing (and simpler, I think). Or arbitrarily copy data between models, including adding columns if necessary, which is what using all the built-in defaults basically allows.
The moment you start pushing unsanitized user-supplied data over opaque datatypes to a model, that's the moment you break any three-tier validation you may've hoped to achieve. If the data comes through a network channel, you'd not push it directly to the model, be it mime-compatible or not, would you?
I think this is veering even further off into OT territory... :-) From a data manipulation perspective, cut/copy/paste is just like DnD but with a clipboard object. If one is concerned about validating the MIME data, then that is a factor regardless of how the data is originally obtained (to varying degrees, perhaps, eg. local clipboard vs. Internet stream :-). I certainly don't want any UI component to do that, but again where/how/if this happens is an implementation detail up to the author(s). The validation needs of any particular data/project may vary from just checking the MIME type to running it through a virus checker... who knows.
Best,
-Max@Max-Paperno said in Reordering rows of QTableView with drag and drop:
The one place this breaks down somewhat is when moving data out of one model and into another.
Or when the consumer of the model wants to handle input differently, be it a View (i.e. UI element) or something else.
OTOH if the data may move between model instances, then again the destination model can know that the source is external, in which case a "move" operation becomes an insert/replace operation.
Data moves between the consumers of the data storage (in this case that'd be the view), not between the actual storages (which is the model in this particular case) is my main point. You wouldn't just expect copying a MySQL data file into a PgSQL engine to simply work, you have that boundary in between them through which you channel all inputs and outputs.
Ah yes, you're right. And maybe where the API is lacking.
Yes, I think I am, but this whole discussion is really irrelevant, simply because that stuff ain't gonna change any time soon. So whatever the "verdict" is, it means nothing in the grand scheme of things.
-
@Max-Paperno said in Reordering rows of QTableView with drag and drop:
The one place this breaks down somewhat is when moving data out of one model and into another.
Or when the consumer of the model wants to handle input differently, be it a View (i.e. UI element) or something else.
OTOH if the data may move between model instances, then again the destination model can know that the source is external, in which case a "move" operation becomes an insert/replace operation.
Data moves between the consumers of the data storage (in this case that'd be the view), not between the actual storages (which is the model in this particular case) is my main point. You wouldn't just expect copying a MySQL data file into a PgSQL engine to simply work, you have that boundary in between them through which you channel all inputs and outputs.
Ah yes, you're right. And maybe where the API is lacking.
Yes, I think I am, but this whole discussion is really irrelevant, simply because that stuff ain't gonna change any time soon. So whatever the "verdict" is, it means nothing in the grand scheme of things.
Well, maybe it's semantics, but to me data moves between storage containers, based on how it is manipulated via the UI, and preferably with integrity checks in the actual storage mechanism before it is written there. Not "between consumers." That's how actual structured DBs are designed, anyway. The "UI" I would edit or run queries in to transfer data between DBs knows nothing about the actual data, nor should it. And just because I'm telling it to "channel" some data from some other DB (using my queries), doesn't mean the destination should just blindly accept that data (eg. even in well-formed data there may be possible relational constraints and other minutiae).
I've been designing DBs and various UIs to interact with them for 25 years, so I think I have a pretty good handle on it by now, or at least what works for me. IMHO, the UI should be as oblivious to the data as possible while still providing a good/appropriate UX. In fact I try to drive the UI with the data (or rather meta-data) as much as possible. Like the QtDesigner property editor, for example (some interesting code there if one were ever inclined to check it out). Because let's face it, who wants to re-write the same basic CRUD UI over and over. This is what the Qt views try to provide, an abstract UI which can be somewhat controlled via meta data from the data/model via an agreed-upon API. And they're relatively easy to customize further, as needed.
Anyway I would also like to point out that the Qt Item model classes do not necessarily need to store any data ("data" is not even in the name ;-). In fact one could argue that they shouldn't, and if one needs persistent data, then they obviously just can't. They're already interfaces to the data, not the actual data. The most obvious examples of this are the
QSQL*Tablemodels, or theQFileSystemModel. Also proxy models, which are clearly just further interface abstraction, not actual data.Cheers,
-Max -
Update/good news: when I remove your overriding implementation of
MyTableView::dropEvent, things work fine (although we lose the selection persistence after the drop, as was the goal of that piece of code).Actually, if I keep the method but replace the delayed row selection by
selectRow(m_dropRow)(as shown below), I get the anomalous behavior. If I remove this line, things work properly but without selecting the moved row afterwards.It seems the delayed row selection does not work in the Mac (makes sense since probably different OSs deal with events differently). Then the row selection happens before the dropMimeData and changes the targeted row, causing the bizarre behavior we observed.
void dropEvent(QDropEvent *e) { if (e->source() != this || e->dropAction() != Qt::MoveAction) return; int dragRow = selectedRow(); QTableView::dropEvent(e); // m_dropRow is set by inserted row if (m_dropRow > dragRow) --m_dropRow; selectRow(m_dropRow); // non-delayed selection has the same effect, so QueuedConnection seems not to work on the Mac. // QMetaObject::invokeMethod(this, // std::bind(&MyTableView::selectRow, this, m_dropRow), // Qt::QueuedConnection); // Postpones selection }@Rodrigo-B said in Reordering rows of QTableView with drag and drop:
Actually, if I keep the method but replace the delayed row selection by selectRow(m_dropRow) (as shown below), I get the anomalous behavior. If I remove this line, things work properly but without selecting the moved row afterwards.
It seems the delayed row selection does not work in the Mac (makes sense since probably different OSs deal with events differently). Then the row selection happens before the dropMimeData and changes the targeted row, causing the bizarre behavior we observed.Firstly, sorry about hijacking your thread.
Second, I think you're right and the queued event is delivered to the view object "too soon" on the Mac. This sort of invocation doesn't come with any promise of linearity. Instead you could try replacing the
invokeMethod()part inMyTableViewwith a single-shot timer (tested and works here, Win10 MSVC17 Qt 5.14.2):// mytableview.h #include <QTimer> ... void dropEvent... { .... QTimer::singleShot(1, this, [this]() { selectRow(m_dropRow); }); }The
1is milliseconds and should be enough, but 10ms won't be noticeable to a user either.The whole thing seems like an awkward workaround, but does seem to work. If I think of anything better, I'll let you know :-)
HTH,
-MaxPS. what was with the
ands intablemodel.cppif()clauses? Does that actually build on something w/out errors? Just curious! -
Well, maybe it's semantics, but to me data moves between storage containers, based on how it is manipulated via the UI, and preferably with integrity checks in the actual storage mechanism before it is written there. Not "between consumers." That's how actual structured DBs are designed, anyway. The "UI" I would edit or run queries in to transfer data between DBs knows nothing about the actual data, nor should it. And just because I'm telling it to "channel" some data from some other DB (using my queries), doesn't mean the destination should just blindly accept that data (eg. even in well-formed data there may be possible relational constraints and other minutiae).
I've been designing DBs and various UIs to interact with them for 25 years, so I think I have a pretty good handle on it by now, or at least what works for me. IMHO, the UI should be as oblivious to the data as possible while still providing a good/appropriate UX. In fact I try to drive the UI with the data (or rather meta-data) as much as possible. Like the QtDesigner property editor, for example (some interesting code there if one were ever inclined to check it out). Because let's face it, who wants to re-write the same basic CRUD UI over and over. This is what the Qt views try to provide, an abstract UI which can be somewhat controlled via meta data from the data/model via an agreed-upon API. And they're relatively easy to customize further, as needed.
Anyway I would also like to point out that the Qt Item model classes do not necessarily need to store any data ("data" is not even in the name ;-). In fact one could argue that they shouldn't, and if one needs persistent data, then they obviously just can't. They're already interfaces to the data, not the actual data. The most obvious examples of this are the
QSQL*Tablemodels, or theQFileSystemModel. Also proxy models, which are clearly just further interface abstraction, not actual data.Cheers,
-Max@Max-Paperno said in Reordering rows of QTableView with drag and drop:
Well, maybe it's semantics, but to me data moves between storage containers, based on how it is manipulated via the UI, and preferably with integrity checks in the actual storage mechanism before it is written there. Not "between consumers." That's how actual structured DBs are designed, anyway. The "UI" I would edit or run queries in to transfer data between DBs knows nothing about the actual data, nor should it. And just because I'm telling it to "channel" some data from some other DB (using my queries), doesn't mean the destination should just blindly accept that data (eg. even in well-formed data there may be possible relational constraints and other minutiae).
This isn't what I meant. The database doesn't spill its data raw, does it? And even if does, nobody's expecting filling in that raw data into another database engine to work. What I meant was, that software's designed as layers over layers, and as data goes trough it gets transformed to prepare it for the next layer.
Firstly, sorry about hijacking your thread.
He specifically asked for this discussion, but if desired I could always fork it.
PS. what was with the ands in tablemodel.cpp if() clauses? Does that actually build on something w/out errors? Just curious!
I disapprove of it, but it's valid c++, every compliant compiler should build it.