Unsolved Lies, Damned Lies, and Statistics
-
@JKSH said in Lies, Damned Lies, and Statistics:
@mzimmers said in Lies, Damned Lies, and Statistics:
"Math's hard; let's go shopping!" (Barbie from the pre men-are-pigs era)
For me, shopping is hard. Too many choices; need to guard against marketers' tactics; need to research to find a good deal; need to haggle or negotiate...
In that case, you don't seem to have a woman. If you did, I would expect her to insist on making all the shopping choices on your behalf, so it wouldn't be an issue... ;-)
["JB: Unreconstructed from the pre-PC era."] -
-
So that's a rather different thing from standard deviation, right. So you make a model, calculate with it, then discover how inaccurate it is by going back and examining the real population, and then make something squared out of it. Is that it?
-
Bonus point for finding the χ key on your keyboard.
While I'm at it.... The other thing I remember the teach banging on about forever was to do with (unlike you I haven't a clue/the will to go find symbols to type) "x-bar" [
xwith a horizontal bar on top of it] versus "mu" [the Greek letter]. x-bar was the mean you got from a sample, while mu was the actual mean, which you didn't know.Now, the problem was something about how you had to phrase what you said about x-bar & mu in your conclusion. I presume this was to do with confidence limits, you were trying to say something like "I'm 95% sure x-bar is within one standard deviation of mu". Only there was some deep rule you had to adhere to in phrasing it some way round with some wording. Like, you couldn't say x-bar or mu was likely to be whatever, because it wasn't subject to probability (perhaps that was for mu, because the mean of the population just is whatever it is, even if you don't what that is, or some-such). So what was that one all about? :)
-
-
@JonB said in Lies, Damned Lies, and Statistics:
- So that's a rather different thing from standard deviation, right. So you make a model, calculate with it, then discover how inaccurate it is by going back and examining the real population, and then make something squared out of it. Is that it?
Yep. If you say you're doing a least squares fit, then chi squared would be how good the fit was - basically the sum of the square of distances between the sampled data and the actual regression curve.
- Bonus point for finding the χ key on your keyboard.
I'm well versed in the greek alphabet, being a physicist and all. ;)
While I'm at it.... The other thing I remember the teach banging on about forever was to do with (unlike you I haven't a clue/the will to go find symbols to type) "x-bar" [
xwith a horizontal bar on top of it] versus "mu" [the Greek letter]. [...] So what was that one all about? :)In principle the real expectation value (or mean) will not coincide with the one you got by sampling. So there's some probability that the sampling mean will be in some range around the real one. That's what this is about - Student's distribution.
Read and abide by the Qt Code of Conduct
-
@kshegunov said in Lies, Damned Lies, and Statistics:
In principle the real expectation value (or mean) will not coincide with the one you got by sampling. So there's some probability that the sampling mean will be in some range around the real one. That's what this is about - Student's distribution.
Yeah, but the nightmare recollection is something about what you were/were not allowed to "say" about something to do with the probability/confidence limits of the relationship between my & x-bar, if you phrased it wrong you lost all your marks....
BTW, on that subject there was something similar (though not as hard to remember as the mu-x-bar one) when you did "proof by induction". You did your
k, then you did yourk + 1. But when you wrote the final conclusion forninstead ofk, you had to phrase that one in a particular way too... ! -
@JonB said in Lies, Damned Lies, and Statistics:
Yeah, but the nightmare recollection is something about what you were/were not allowed to "say" about something to do with the probability/confidence limits of the relationship between my & x-bar, if you phrased it wrong you lost all your marks....
Well, no idea. Formally speaking it's probably wrong to say that x bar is the expectation value (which is μ), but if using jargon you usually equate one with the other.
BTW, on that subject there was something similar (though not as hard to remember as the mu-x-bar one) when you did "proof by induction". You did your k, then you did your k + 1. But when you wrote the final conclusion for n instead of k, you had to phrase that one in a particular way too... !
Well, induction works like: "if granted for k, it is proven for k + 1, and there's some initial k for which the statement holds, then it holds for all k after the initial one" (and requires k be integer as well). I don't remember anything related to the phrasing that'd be similar to what you describe.
Read and abide by the Qt Code of Conduct
-
@kshegunov
You inspired me to Google. There obviously is a phraseology issue. I came across https://www.thestudentroom.co.uk/showthread.php?t=859544 :I don't know how you should go about concluding it; at A-level our teacher was really picky about how the wording we used to finish it (we learnt some ridiculous phrase and wrote it down at the end of every proof), but since then I haven't met anyone who really seems to care.
And there was something similar about x-bar & mu. He prolly had the same teacher as I did :)
-
Oh, shame I have not discovered this thread earlier. Cool stuff and a very pleasant read!
And to celebrate, you've all got upvotes :)
-
Maybe. You might be thinking about necessary and sufficient conditions, which comes more often than not when proving math statements ...
-
@JonB said in Lies, Damned Lies, and Statistics:
BTW, on that subject there was something similar (though not as hard to remember as the mu-x-bar one) when you did "proof by induction". You did your
k, then you did yourk + 1. But when you wrote the final conclusion forninstead ofk, you had to phrase that one in a particular way too... !🤔
Quod erat demonstrandum?All jokes aside,
You usually have a induction start, where you formulate your asumption:
for example:
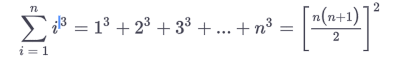
than one shows, it holds true for a specific value e.g. 1
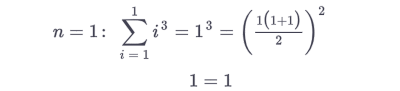
Than the "fun" part begins when you show it doesn't matter what value you choose for example, k and k +1
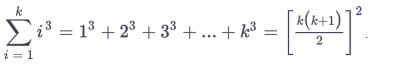
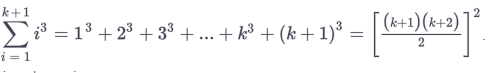
than you show that your asumptions hold true
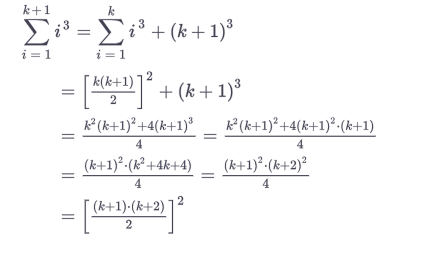
and your done, I never wrote anything else extra in my life after that.
or do you mean you had to write down the structure of the proof?
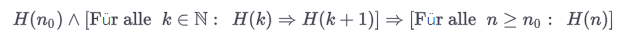
sorry for the german text: Für alle = for all = ∀Be aware of the Qt Code of Conduct, when posting : https://forum.qt.io/topic/113070/qt-code-of-conduct
Qt Needs YOUR vote: https://bugreports.qt.io/browse/QTQAINFRA-4121
Q: What's that?
A: It's blue light.
Q: What does it do?
A: It turns blue. -
@J.Hilk
That is very pretty! But, no, it was not just a question of writing QED. I refer you to the quote I pasted above, where you can see that another person has the same recollection as I have about some very specific wording we were made to use, which we have now forgotten. It was something about what we had to write for the move to generalise from1/k/k + 1ton. And something similar in the way of "special wording" when we talked about the confidence-relationship between x-bar & mu in statistics....